위 데이터는 stack()을 하면 A, B 컬럼이 MultiIndex 로 추가되며 A, B 컬럼 데이터 포인트가 배치된다.
1
df.stack()
first second
bar one A -1.301694
B -0.013259
two A -0.197846
B 0.879890
baz one A 0.718211
B -0.739434
two A -0.140217
B 0.071260
foo one A -1.142268
B -2.606413
two A 1.119145
B 0.109402
qux one A -0.504167
B -1.703280
two A 1.064976
B 1.011060
dtype: float64
1 2
df2 = df[:4] df2
A
B
first
second
bar
one
-1.301694
-0.013259
two
-0.197846
0.879890
baz
one
0.718211
-0.739434
two
-0.140217
0.071260
1 2
stacked = df2.stack() stacked
first second
bar one A -1.301694
B -0.013259
two A -0.197846
B 0.879890
baz one A 0.718211
B -0.739434
two A -0.140217
B 0.071260
dtype: float64
> with np.printoptions(precision=3): > print( np.array([2.0]) / 3 )
pandas 숫자 출력 형식 변경
pandas에서 몇 가지 옵션을 바꾸는 방법을 정리해 보자. pandas의 옵션은 pd.options 를 사용한다.
pd.options.display
출력의 형태, 표기를 변경하는 것은 pd.options.display 아래에 있다. 여기서 사용할 수 있는 옵션은 describe_option() 으로 확인할 수 있다.
1 2 3 4 5 6 7
> pd.describe_option() compute.use_bottleneck : bool Use the bottleneck library to accelerate if it is installed, the default isTrue Valid values: False,True [default: True] [currently: True] ...
- row, column 출력 개수 조정
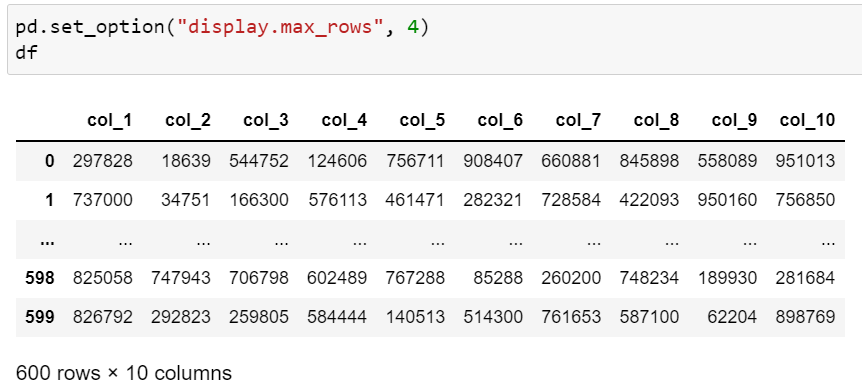
pd.options.display.max_rows : 표를 출력할 때 최대 행 수입니다.
pd.options.display.min_rows : 표를 출력할 때 최소 행 수입니다.
1 2 3 4 5
import pandas as pd > pd.options.display.max_rows 60 > pd.options.display.min_rows 10
pd.describe_option(OPTIONS) 를 사용하면 해당 옵션에 대한 설명을 출력해 준다.
1 2 3 4 5
> pd.describe_option("max_rows") display.max_rows : int If max_rows is exceeded, switch to truncate view. Depending on `large_repr`, objects are either centrally truncated or printed as a summary view. 'None' value means unlimited.
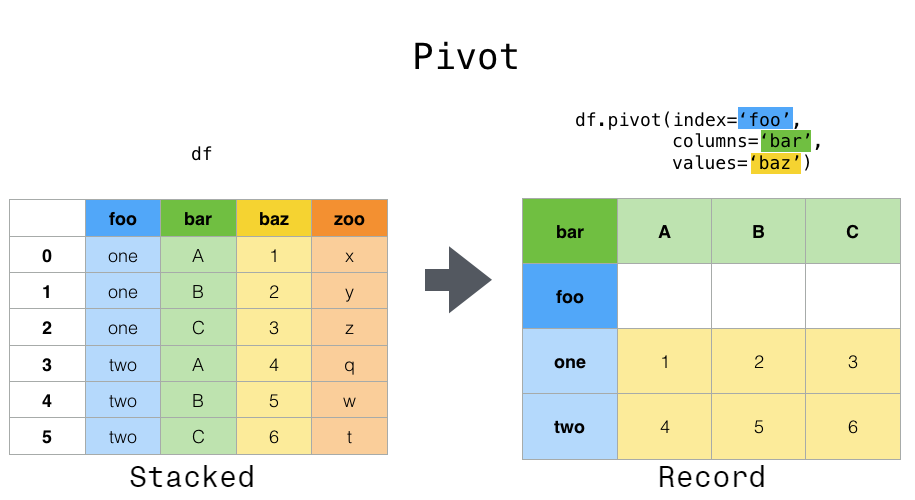
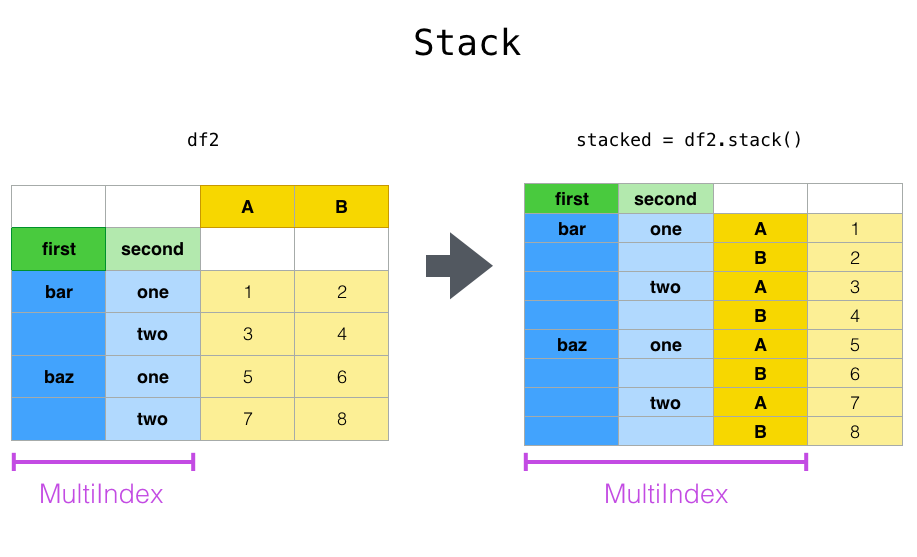
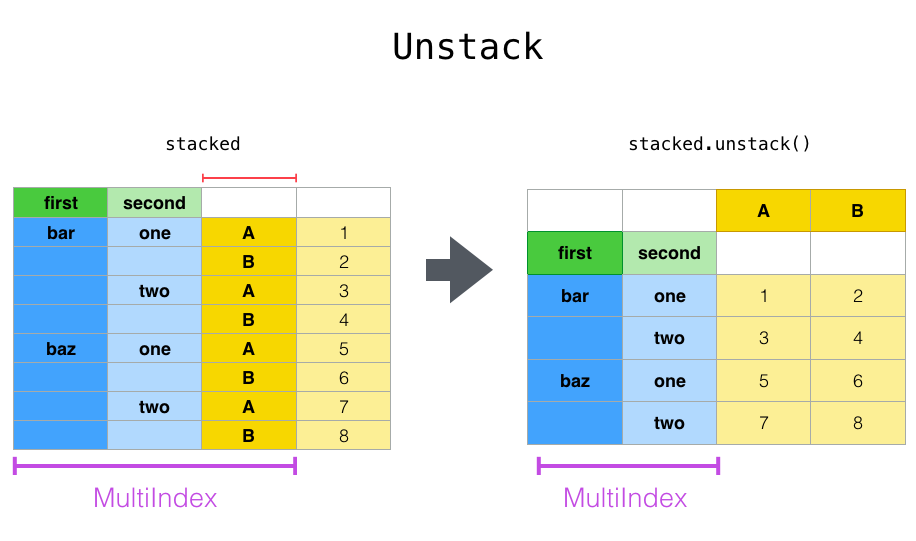
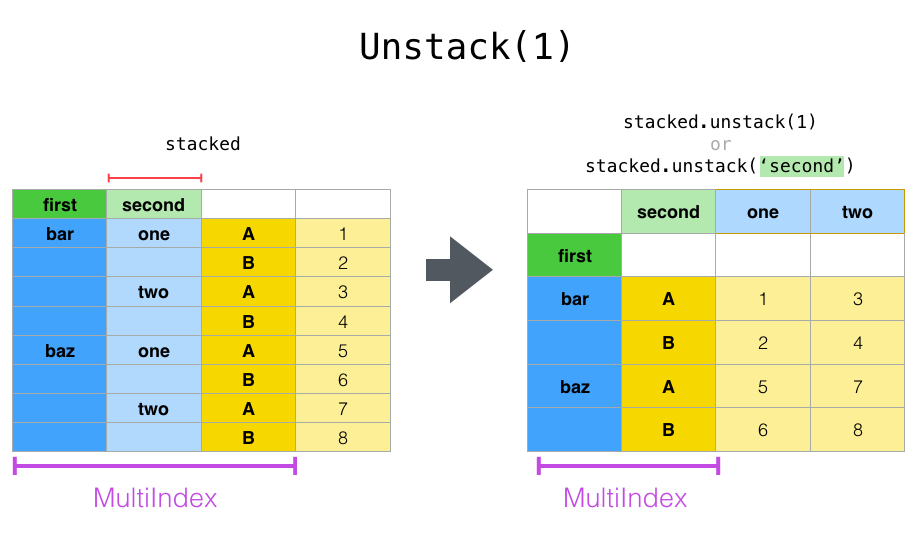
 이미지 참조
이미지 참조