[요약] 영상 분야에서의 인공지능 발달 단계에 따른 데이터와 모델의 변화
다음 2개의 글을 요약하고 설명을 추가로 검색해 요약해 두었다.
- 인공지능 학습용 영상 데이터 기술 동향, IITP 주간기술동향 1988호, 임철홍
- 영상 분야에서의 인공지능 발달 단계에 따른 데이터와 모델의 변화, IITP 주간기술동향 2071호, 김혜진_한국전자통신연구원 책임연구원
2023/01/15 요약 작성
1 |
[요약] 영상 분야에서의 인공지능 발달 단계에 따른 데이터와 모델의 변화
IITP 주간기술동향 2071호등록자 / 영상 분야에서의 인공지능 발달 단계에 따른 데이터와 모델의 변화
- 김혜진_한국전자통신연구원 책임연구원
I. 발전
1세대
1950년대에서 80년대에 이르기까지의 규칙ㆍ지식에 기반을 둔 추론 시스템
2세대
제프리 힌튼(Geoffrey Hinton)과 얀 리쿤(Yann LeCun), 요슈아 벤지오(Yoshua Bengio)에 의해 시작된 특정 문제에 국한된 데이터셋으로부터 학습을 통해 습득하는 AI 2세대라 할 수 있다
3세대
범용적인 문제를 해결할 수 있는 인공지능
인공지능 하이프 사이클
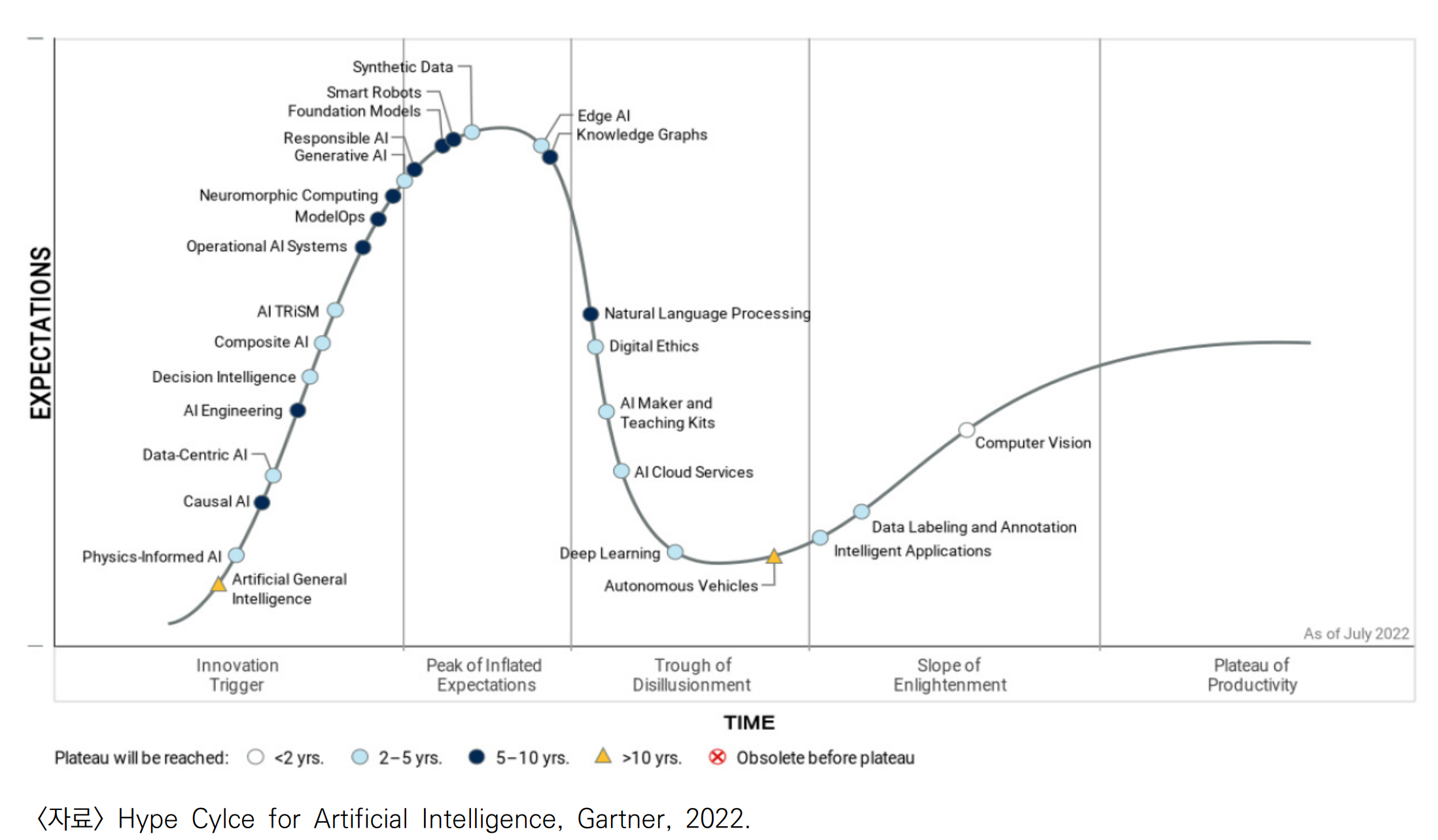
II. AI 2세대의 데이터
최근 2세대 AI 들은 널리 알려진 형태로, 다양한 분야에서 데이터를 모으려는 노력을 바탕으로 발전되고 있다. 다양한 공개 데이터세트를 비교해 공개된 데이터셋에서 성능에 대한 비교를 포함하는 것이 거의 필수 요소가 되었다.
이미지 분류 데이터 세트
인공지능 학습용 영상 데이터 기술 동향, IITP, 주간기술동향 1988 에 정리
MNIST
숫자 10종류에 대해 7만 장의 이미지로 구성되어 있다
ImageNet
영상 downstream task에서 pretrained network로 사용되고 있는 데이터셋 중 하나로, 1,000종류, 14,197,122의 이미지로 구성되어 있다.
CIFAR
CIFAR-10, CIFAR-100으로 각각 10종류, 600장과 100종류,60,000장의 이미지가 있다
영상에서 객체 검출 데이터 세트
이미지의 상황을 이해하여 캡션 등을 자동으로 생성하기 위한 연구가 진행되면서 다중 객체 인식을 기반으로 장면 설명, 객체 간의 관계 등의 데이터가 필요하게 되었다
- MS COCO[1], PASCAL VOC 2012[2] 등이 객체 검출을 목적으로 구축된 데이터셋이다.
- 구글 Open Image
- STANDFORD와 YAHOO의 Visual Genome
객체 검출 알고리즘으로 널리 알려진 R-CNN, YOLO 계열의 알고리즘들도 모두 이 데이터셋을 기반으로 개발되었다.[1][2]
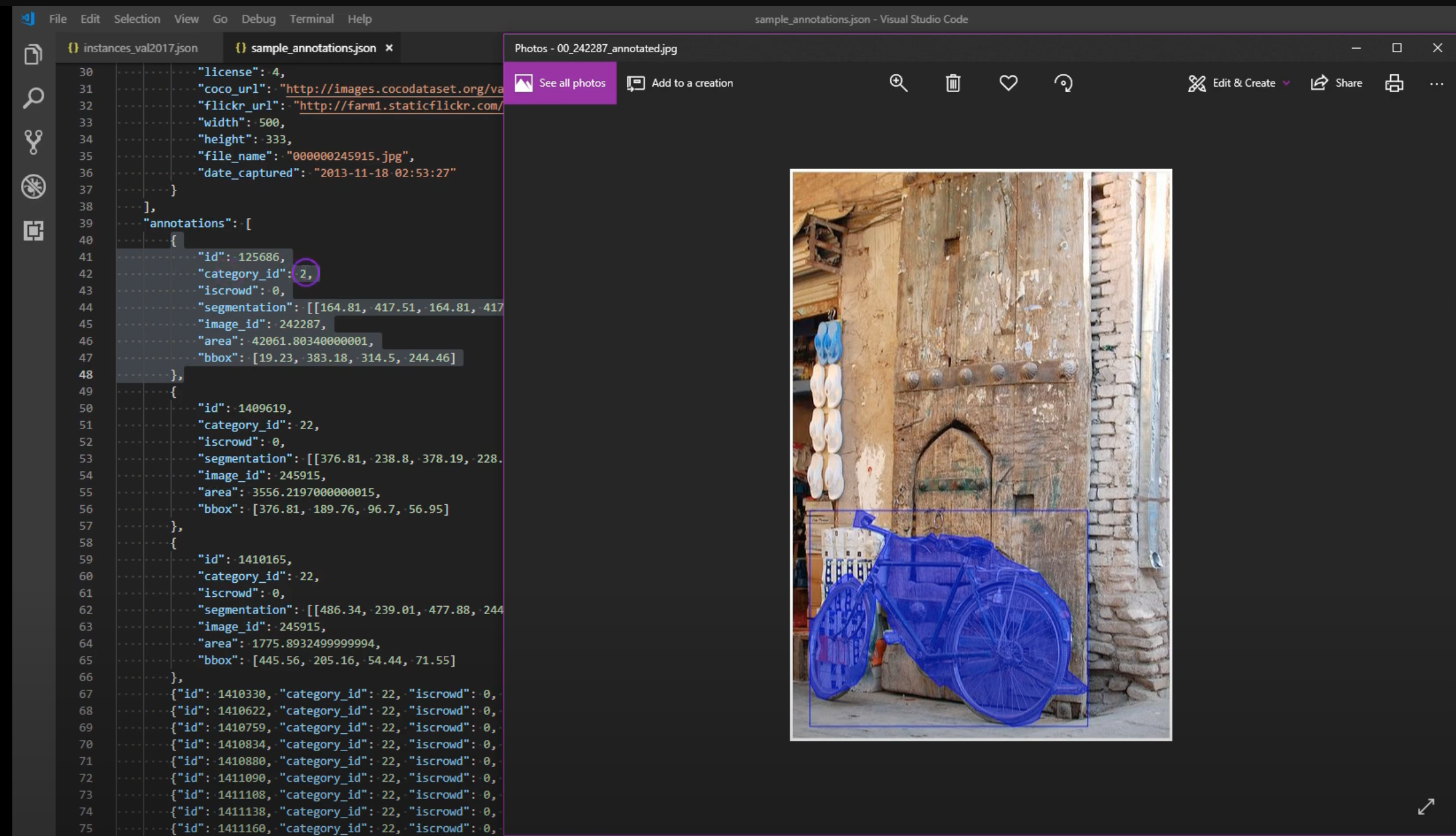
MS COCO (Common Object in COntext)
이미지의 객체 인식, 분할, 캡션 인식을 위한 공개된 데이터 셋이다. 330,000개의 이미지에서 80개 분류 1,500,000개의 객체 인스턴스를 가지고 있다. Flickr의 이미지를 기반으로 학습과 테스트가 진행되었다

COCO 홈페이지 데이터 셋 메뉴에서 explorer를 선택하면 직접 데이터 셋을 볼 수가 있는데, 위 그림 처럼 선택된 분류 객체가 분할된 이미지를 볼 수 있다. 앞에 있는 것은 ‘person’이 선택되어 사람 객체가 분할되어 보이며, 뒤에 있는 것은 ‘car’가 선택되어 자동차 객체가 분할되어 보인다. [2]
데이터 셋은 이미지 원본파일과 이를 설명하는 annotation 파일로 구성된다. annotation 파일은 captions, instances, person_keypoints 파일로 구성되며,json 형태로 되어 있다. 각 json 파일은 전체 이미지에 대해 하나로 구성되어 있어 크기 매우 크다.
annotation 에는 개체에 대한 정보가 info, license, images, annotations, categories 등으로 제공된다.
Open Image
Open Image는 구글에서 공개한 오픈 이미지 데이터 셋이다. 이미지 수준 레이블(image-level labels), 객체 경계 상자(object bounding boxes), 객체 분할 마스크(segmentation masks), 시각적 관계(visual relationships), 나레이션(localized narratives)을 포함하는 데이터 이다.
- 2016년 처음 공개
- 2018년 V4
- 2020년 2월 V6
Open Image V4
Open Image V4는 9,178,275개의 이미지에서 30,113,078개의 이미지 수준 레이블과 15,440,132개의 객체 경계 상자를 가지고 있으며, 374,768개의 시각적 관계를 나타내고 있다.
- Flickr 에서 고해상도, creative common, crowd sourcing 라이센스 위주로 수집
- 이미지 분류는 구글 데이터셋 JFT 의 19,794개 분류 체계
- Announcing Open Images V4 and the ECCV 2018 Open Images Challenge
Bounding Box
객체 경계 상자는 이미지에서 객체 인식에 활용되기 위한 정보이다.
 그림 - google ai blog
그림 - google ai blog
바운딩 박스를 통해서 객체 경계 상자에 나타난 객체들은 서로 관계를 맺고 있으며, Open Image에서 이들의 시각적 관계가 아래 같이 같이 점선박스로 보여진다.
 그림 - google ai blog: https://ai.googleblog.com/2020/02/open-images-v6-now-featuring-localized.html
그림 - google ai blog: https://ai.googleblog.com/2020/02/open-images-v6-now-featuring-localized.html
Open Image V5
Open Image V5에서는 350개 카테고리의 2,800,000개의 객체 분할 마스크가 추가되었다
Open Image V6
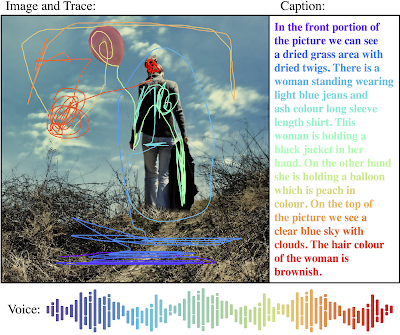
Open Image V6에서는 675,000개의 나레이션이 추가되었다.
나레이션은 이미지를 설명하는 캡션과 음성 설명이 포함되어 있고 음성 설명과 캡션에 해당하는 사물이나 동작등을 마우스로 그린 트레이스가 포함되어 있다
Visual Genome
Visual Genome은 지식 베이스의 이미지 데이터 셋으로 이미지의 구조를 언어와 연결하려고 노력하고 있다. 108,077개의 이미지에 5,400,000개의 지역 설명과 3,800,000 개의 객체, 2,800,000개의 속성, 2,300,000개의 관계로 구성되어 있다.
데이터 셋은 지역 설명(region descriptions), 객체(Objects), 속성(attributes), 관계(relationships), 지역 그래프(region graphs), 장면 그래프 (Scenegraphs) 및 질문답변으로 구성되어 있다
 그림 - https://paperswithcode.com/paper/visual-genome-connecting-language-and-vision/
그림 - https://paperswithcode.com/paper/visual-genome-connecting-language-and-vision/
지역 설명은 객체의 상태나 동작을 나타내고 있으며, 이들은 객체와 속성으로 나누어 설명되며, 각각 그래프의 형태로 간단하게 표현될 수 있다. 이미지의 여러 지역(region)은 합쳐져서 전체 장면 설명을 하는 장면 그래프로 표현된다.
1 |
1 |
의미론적 분할(Semantic Segmentation)
이미지 분류와 객체 검출과도 연관이 깊은분야로, Cityscapes[3], ADE20K[4], PASCAL VOC2012[5] 등이 있다
- Cityscapes는 도시 환경에서의 의미론적 분할을 ADE20K는 sky, road, grass, person,car, bed 등 150종목에 대한 장면 중심의 영상 분할을 다룬다.
- PASCAL Context는 PASCALVOC 2010의 확장판으로 400종 이상의 레이블을 제공한다.
거리 추정
이미지와 영상에서 빼놓을 수 없는 분야 중 하나로 실외 거리 추정을 위해서는 KITTI 데이터셋[6]이 실내는 NYU v2[7] 데이터셋이 널리 활용되어 왔다
이미지 생성 분야
2세대 AI는 데이터가 충분할수록 성능 향상을 기대할 수 있는 학습 기반 인공지능으로 이미지 생성 분야는 이러한 데이터를 “생성” 하는 데 활용을 기대할 수 있기 때문에 데이터 관점에서 2세대 AI에서의 이룬 괄목할 만한 성과 중 하나라 할 수 있다.
널리 알려진 이미지 생성 데이터셋으로는
CelebA
10,177명의 유명인사에 대한 202,599 얼굴이미지로 이루어졌다.
FFHQ
연령, 인종, 다양한 배경 변화를 가진 70,000 고해상도 영상들로 이루어졌다.
III. 데이터 부족에 대한 논의
기존에 AI 연구는 빅데이터를 가정하고 있으나 실제 데이터 분석 사례에서는 빅데이터가 아닌 경우가 많다.데이터가 적고 레이블에 일관성이 없는 경우에는 모델을 아무리 개선을 한다고 해도(즉, model-centric 접근 방식을 적용) 성능을 개선하기 어렵다는 것을 2021년 3월 25일 Deep Learning AI에서 주최한 앤드류 응 교수가 보여주었다.
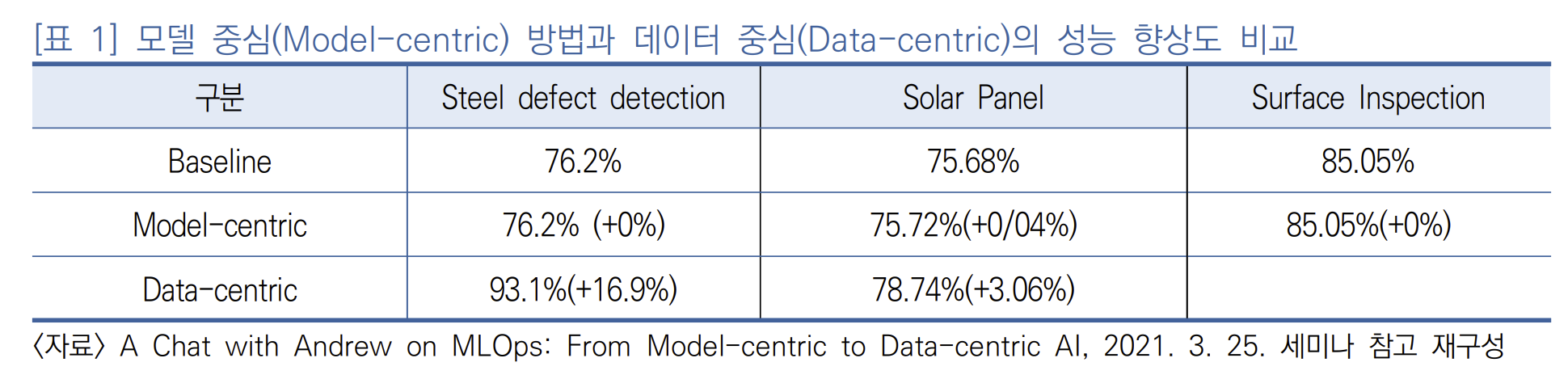
대응
이러한 문제를 해결하기 위해 컴퓨터 비전 분야의 저명한 학회인 CVPR(Computer Vision and Pattern Recognition) 학회에서는 2020년부터 2022년에 걸쳐 limited labeled data와 관련된 워크샵을 다루었으며,
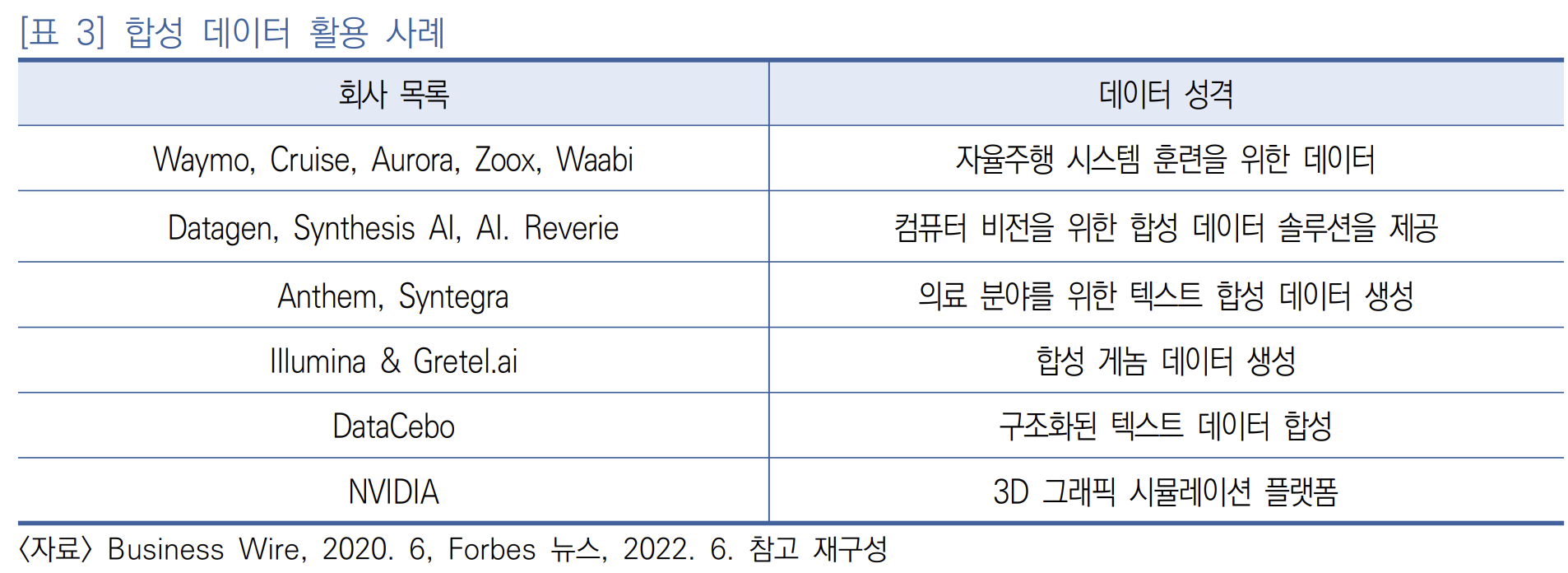
합성 데이터를 만들어 데이터 부족 문제를 극복하려는 많은 시도가 있었다. BMW와 같은 자동차 제조업체뿐만 아니라, 은행, 공장, 병원, 로봇 등 다양한 분야에서 이러한 합성 데이터를 기반으로 AI 모델 학습에 적용하고 있다
가트너, 미래는 합성데이터
2021년 6월 보고서에 따르면 2030년에는 AI의 대부분의 데이터가 합성 데이터를 기반으로 생성될 것으로 보고, 2024년까지 AI 및 분석에 사용되는 데이터의 60%가 이 합성데이터를 사용할 것이라고 예측
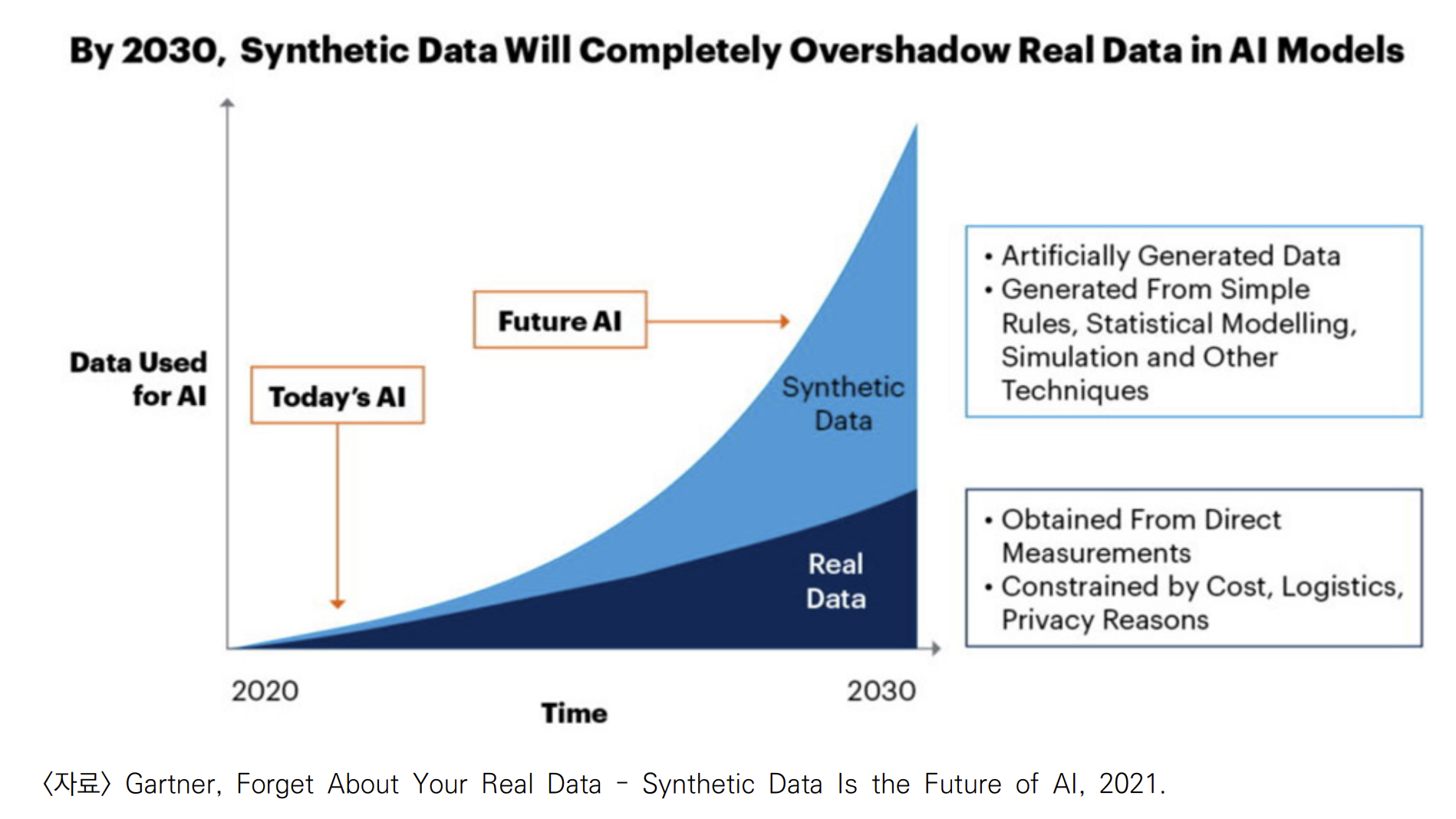
실제 데이터를 얻는 비용이 인건비 수준에서 많게는 수십억에 이르는 문제가 있기 때문이다. 반면에, 합성 데이터를 만들어 더욱 정확한 레이블을 얻을 수 있는 경우도 많다.
예를 들어, 거리 추정 데이터의 경우 센서의 정확도가 한계가 있어 픽셀에 매핑되는 거리 레이블의 정확도가 떨어진다. 반면, 합성 데이터의 경우에는 모든 픽셀에서 높은 정확도의 거리 레이블링 데이터를 얻을 수 있다. 즉, 합성데이터는 앞서 언급한 앤드류 응 교수가 지적한 레이블의 품질 저하 문제를 일으키지 않기 때문에 더 정확한 모델 학습이 가능할 수 있다.
합성데이터
합성 데이터를 얻는 방법에는 시뮬레이션으로 얻는 방법, AI 기법(GAN, VAE, Normalizing Flow) 또는 도메인 랜덤화 등이 널리 알려져 있다. 최근에는 확산 모델(Diffusion model)[15]과 NeRF[16]의 등장으로 한층 더 정교해졌다
대표적인 확산 모델로
- 오픈 AI의 DALL-E 2의 백본 모델이 있다.
- 확산 오토인코더(Diffusion Autoencoder)와 같이 의미론적 의미가 있는 확산 모델도 제안
- NeRF는 기존의 방법들이 시점에 대한 변화를 주기 어려웠던 점에 반해, 차량 앞면을 보고, 뒷면을 생성할 수 있는 등 다양한 시점에서의 영상을 생성할 수 있다. 더 나아가, 2D 이미지에서 3D 이미지를 생성함으로써 영상의 스케일 변화까지 줄 수 있어 데이터 합성에 있어 큰 전환점을 마련하였다
DALL-E 2 backbone Model
이미지와 텍스트의 관계를 학습하고, 이를 통해, 영상에 다양한 변화를 줄 수 있게 했을 뿐만 아니라 텍스트를 통해 고해상도의 이미지를 생성
부족한 데이터 문제를 극복하기 위한 방법으로 자기지도학습(self-supervised learning) 방법
자기지도학습 방법은 비지도학습과 유사하게 레이블 없는 데이터셋에서 사용자가 직접 정의한 작업(pretext task)를 목표로 학습시키게 된다. 이 때, 이 작업은 데이터에서 레이블로 사용될 수 있는 정보를 활용하여 지도학습처럼 학습시키게 되어 데이터 부족 문제를 우회적으로 풀 수 있게 된다.
IV. AI 3세대를 지향하는 디딤돌 데이터셋의 등장
자기주도학습 데이터세트
하나의 태스크에 국한되어 있지 않은 응용성을 가진 데이터셋이 점점 더 다양하게 등장하고 있다. 이러한 현상은 영상 내에서만 국한되지 않고, 텍스트를 포함하고 더 나아가 구조화된 데이터, 3D 신호 데이터 등 점점 더 다양한 데이터셋을 포함하는 방향으로 확장되고 있다. 이렇게 이기종의 빅데이터를 학습시키게 되면 파운데이션 모델(foundation model)을 얻을 수 있게 된다. 이러한 파운데이션 모델은 대규모 데이터로 사전학습되어 다른 모델에 지식을 전달해 줄 수 있는 모델을 의미한다
자기주도학습이 비지도학습과 달리 지도학습에 견줄 수 있는 성능을 획득하게 된 것은 Pretext task 단계에서 큰 데이터셋을 활용할 수 있는 덕분이다.
KITTI 데이터셋
KITTI 데이터셋은 거리 추정을 포함한 2D/3D 객체 검출, 도로 환경에서의 의미론적 분할 정보, 주행거리계(odometry), 도로 환경에서 객체 추적, 차선 검출 등 다양한 정보를 포함하고 있다.KITTI 데이터셋이 자율주행을 위해 필요로 하는 데이터셋을 포함하고 있어 자율주행 기술 발전에 공헌한 바가 크기때문이다
주요 블로그 글
파운데이션 모델:
파운데이션 모델은 스탠포드의 인간중심 인공지능연구소에서 2021년 처음으로 대중화한 용어로 소개되었다. 그러나 파운데이션 모델의 가능성은 먼저 초거대 AI로 불리는 모델
들인 BERT, DALL-E 2, GPT-3로부터 시작되었다.
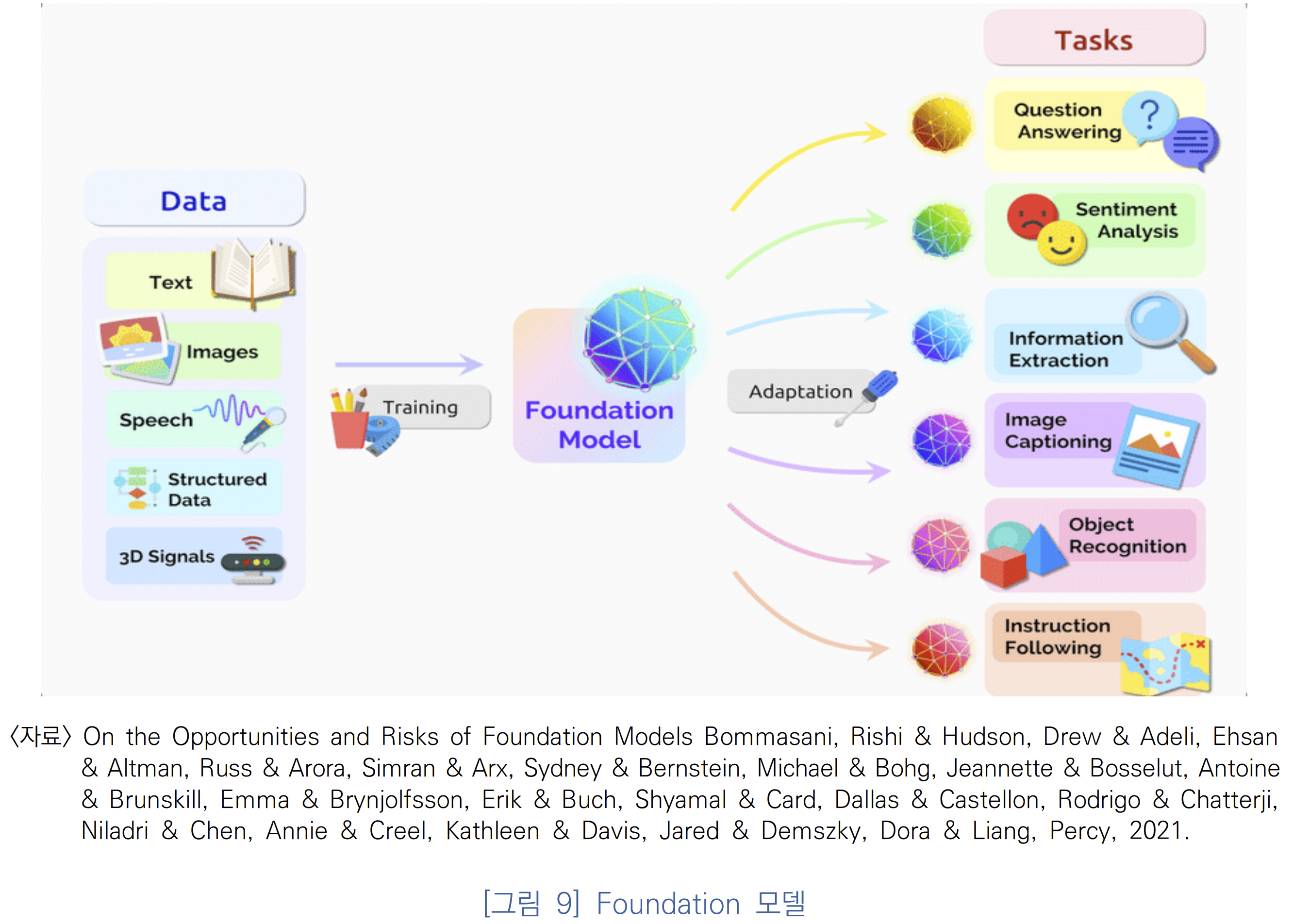
초거대 AI는 초기에는 언어모델에 국한되었으나, 점차 이미지를 함께 포함하는 모델로, 또는 다양한 언어를 포함하는 모델로 확장되고 있다
초거대 AI
초거대 AI는 초기에는 언어 모델에 국한되었으나, 점차 이미지를 함께 포함하는 모델로, 또는 다양한 언어를 포함하는 모델로 확장되고 있다([표 4] 참조)
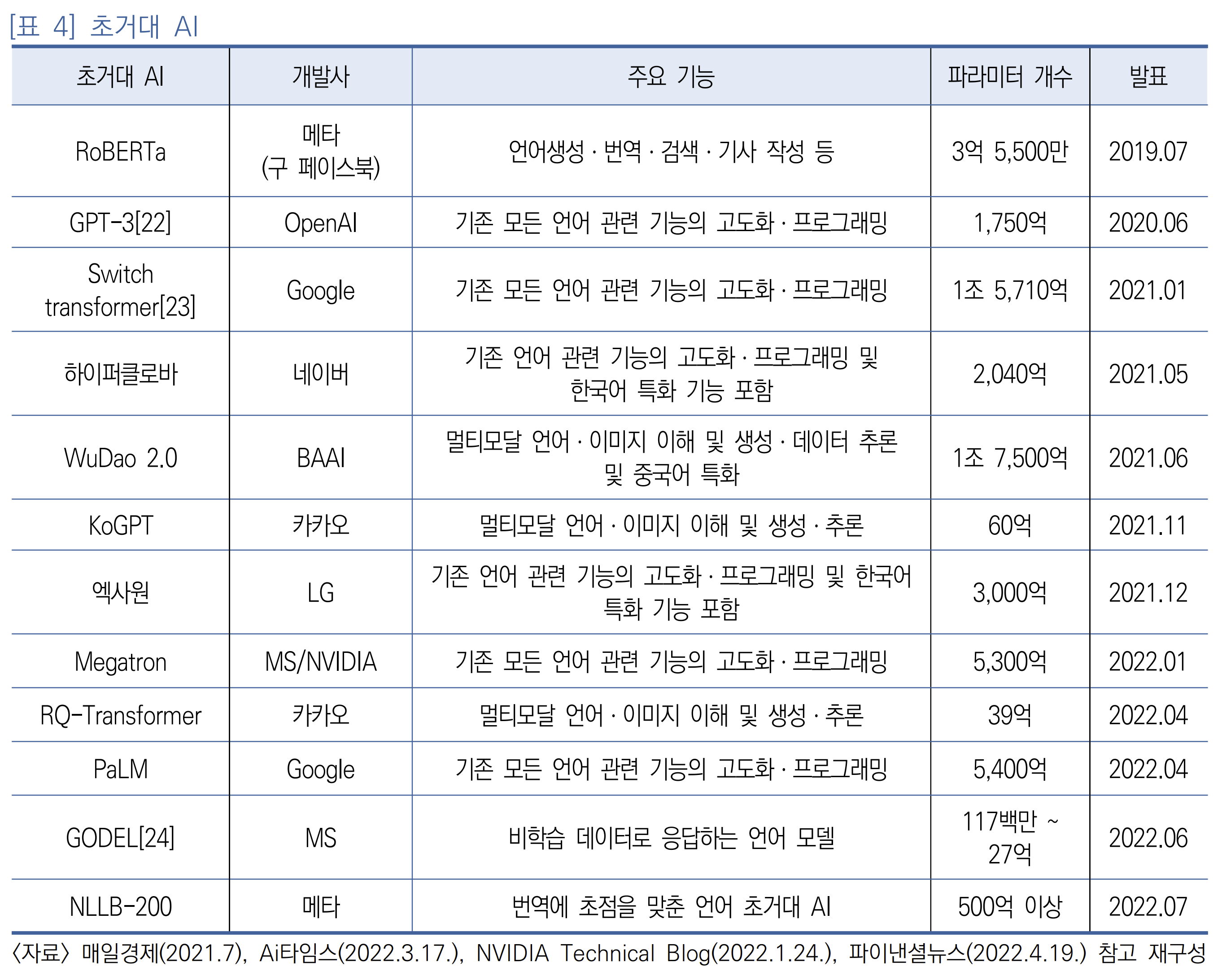
최근 발표된 GODEL은 주제를 변경하고 학습시에 주어지지 않은 이벤트에 대한 질문에 응답할 수도 있고, 구조화되지 않은 텍스트를 통해 검색할 수 있게 하며, 대화식 질문에도 응답이 가능한 모델로 인공지능 3세대의 자격요건에 한층 더 가까워졌다.
GODEL(Grounded Open Dialogue Model)
가상비서나 챗봇과 같은 대화 에이전트가 레스토랑 추천과 같은 주제별 전문 지식을 제공하는 것 외에도 지역의 역사나 최근 스포츠 경기에 대한 대화에 참여할 수 있다면 어떨까? 또한 에이전트의 응답이 최근의 이벤트와 이슈를 지속적으로 반영한다면 어떨까?
고델은 마이크로소프트가 2019년에 발표한 최초의 대규모 사전 훈련 언어 모델인 DialoGPT의 개선된 대화형 언어 모델이다. 고델은 응답할 수 있는 쿼리 유형과 가져올 수 있는 정보 소스에 제한이 없는 대화 에이전트를 만드는 것을 목적으로 한다.
- https://www.microsoft.com/en-us/research/project/godel/
- 기사/블로그: 마이크로소프트, 비학습 데이터로 응답하는 언어 모델 “고델(GODEL)” 공개
마이크로소프트에 따르면 고델은 대화 에이전트에 대화 내용 뿐만 아니라 훈련에 사용된 데이터에 포함되지 않은 외부 정보를 기반으로 응답을 생성할 수 있는 기능을 제공한다.
지역의 레스토랑에 대한 추천을 얘기하는 갑자기 최근에 발생한 토네이도에 대한 얘기를 했을때 웹에서 관련 정보를 가져와 응답하고 원래 주제로 돌아 가려고 하는 내용을 보여준다.
 그림 - https://www.microsoft.com/en-us/research/blog/godel-combining-goal-oriented-dialog-with-real-world-conversations/
그림 - https://www.microsoft.com/en-us/research/blog/godel-combining-goal-oriented-dialog-with-real-world-conversations/
대용량 데이터 세트의 구축이 초거대 AI 개발 근간
초거대 AI의 개발은 근간이 되는 대용량 데이터셋이 구축된 덕분이다.
- 구글의 경우 18억 건의 데이터셋을 구축했고
- 오픈 AI의 경우 10억 건 수준으로 알려져 있다[25].
- 카카오 브레인은 정제를 거친 20억 건 수준의 이미지ㆍ테스트 데이터를 구축하고 있다[26].
영상을 중심으로 하는 파운데이션 모델은 비전-언어 사전학습 모델(Vision-Language Pretraining:VLP)의 형태로 CLIP, Florence, CoCa 등이 알려져 있다. Open AI의 CLIP은 이미지와 자연어 4억 개 쌍의 관계를 학습한 것이다.
마이크로소프트의 Florence 모델은 30억 개의 이미지-텍스트 쌍의 데이터에 이 중 필터링을 통해 9억 쌍을 얻은 FLOD-9M 데이터셋을 구축하여 학습한 모델이다.
구글의 CoCa는 다양한 벤치마크에서 우수한 성능을 보였을 뿐만 아니라 ImageNet에서의 Zero-shot 성능이 86.3%로 매우 우수한 성능을 얻었다. Zero-shot에서의 우수한 성능은 다양한 하위 과제에서 높은 성능을 얻을 가능성을 보여준다. 즉, 영상만의 대용량보다는 언어 데이터와 쌍을 이루어 학습함으로써 더욱 좋은 표현력을 얻을 수 있게 되었다.
양질의 충분한 데이터 문제
인공지능 모델은 양질의 데이터만 충분하다면 문제
를 해결할 수 있다는 생각이 널리 퍼져 있다. 한편, 양질의 데이터는 비용 문제, 레이블링의
품질 문제, 보안 등으로 충분한 확보가 어려움도 널리 공감을 받고 있다. 합성 데이터 알고리
즘들의 발전과 파운데이션 모델에 기반하여 적응(adaptation)에 필요한 적은 데이터만 확보
하면 되도록 하는 기술의 발전으로 제3세대 인공지능은 스스로 문제에 대한 데이터를 확보 할 수 있는 AI로 한 걸음씩 다가가고 있다
[1]: 인공지능 학습용 영상 데이터 기술 동향, IITP 주간기술동향 1988호, 임철홍
[2]: 영상 분야에서의 인공지능 발달 단계에 따른 데이터와 모델의 변화, IITP 주간기술동향 2071호, 김혜진_한국전자통신연구원 책임연구원